| Section 7.2: Full Text |
Chapter
Contents | View Full Text | View
Bullet Text |
| Database Management Systems |
| Types of Databases |
| Window on Organizations |
THE DATABASE APPROACH
TO DATA MANAGEMENT
Database technology can cut through many of the problems a traditional
file organization creates. A more rigorous definition of a database is
a collection of data organized to serve many applications efficiently
by centralizing the data and controlling redundant data. Rather than storing
data in separate files for each application, data are stored so as to
appear to users as being stored in only one location. A single database
services multiple applications. For example, instead of a corporation
storing employee data in separate information systems and separate files
for personnel, payroll, and benefits, the corporation could create a single
common human resources database. Figure 7-4 illustrates the database concept.
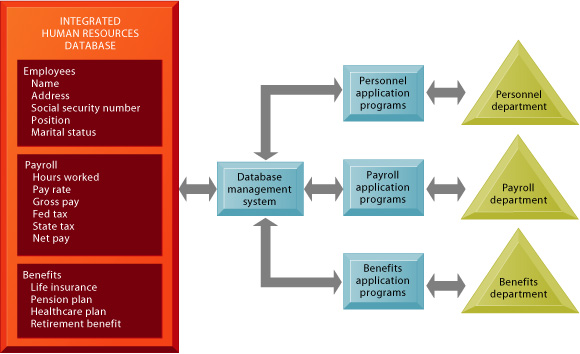 |
FIGURE 7-4 The contemporary database environment
A single human resources database serves multiple applications and also
enables a corporation to easily draw together all the information for
various applications. The database management system acts as the interface
between the application programs and the data.
A database management system (DBMS) is simply the software that permits an organization to centralize data, manage them efficiently, and provide access to the stored data by application programs. The DBMS acts as an interface between application programs and the physical data files. When the application program calls for a data item, such as gross pay, the DBMS finds this item in the database and presents it to the application program. Using traditional data files, the programmer would have to specify the size and format of each data element used in the program and then tell the computer where they were located. A DBMS eliminates most of the data definition statements found in traditional programs.
The DBMS relieves the programmer or end user from the task of understanding where and how the data are actually stored by separating the logical and physical views of the data. The logical view presents data as they would be perceived by end users or business specialists, whereas the physical view shows how data are actually organized and structured on physical storage media. The database management software makes the physical database available for different logical views presented for various application programs. The logical description of the entire database showing all the data elements and relationships among them is called the conceptual schema, whereas the specifications of how data from the conceptual schema are stored on physical media is termed the physical schema or internal schema. The specific set of data from the database, or view, that is required by each user or application program is termed the subschema. For example, for the human resources database illustrated in Figure 7-4 an employee retirement benefits program might use a subschema consisting of the employees name, address, social security number, pension plan, and retirement benefits data.
A database management system has three components:
- A data definition language
- A data manipulation language
- A data dictionary
Most DBMS have a specialized language called a data manipulation language that is used in conjunction with some conventional third- or fourth-generation programming languages to manipulate the data in the database. This language contains commands that permit end users and programming specialists to extract data from the database to satisfy information requests and develop applications.
The most prominent data manipulation language today is Structured Query Language, or SQL. End users and information systems specialists can use SQL as an interactive query language to access data from databases, and SQL commands can be embedded in application programs written in conventional programming languages.
The third element of a DBMS is a data dictionary. This is an automated or manual file that stores definitions of data elements and data characteristics, such as usage, physical representation, ownership (who in the organization is responsible for maintaining the data), authorization, and security. Many data dictionaries can produce lists and reports of data use, groupings, program locations, and so on.
Figure 7-5 illustrates a sample data dictionary report that shows the size, format, meaning, and uses of a data element in a human resources database. A data element represents a field. In addition to listing the standard name (AMT-PAY-BASE), the dictionary lists the names that reference this element in specific systems and identifies the individuals, business functions, programs, and reports that use this data element.
 |
FIGURE 7-5 Sample data dictionary report
The sample data dictionary report
for a human resources database
provides helpful information,
such as the size of the data element,
which programs and
reports use it, and which group
in the organization is the owner
responsible for maintaining it.
The report also shows some of
the other names that the organization
uses for this piece of data.
Most data dictionaries are entirely passive; they simply report. More advanced types are active; changes in the dictionary can be automatically used by related programs. For instance, to change ZIP codes fromfive to nine digits, one could simply enter the change in the dictionary without having to modify and recompile all application programs using ZIP codes.
In an ideal database environment, the data in the database are defined only once and used for all applications whose data reside in the database, thereby eliminating data redundancy and inconsistency. Application programs, which are written using a combination of the data manipulation language of the DBMS and a conventional programming language, request data elements from the database. Data elements called for by the application programs are found and delivered by the DBMS. The programmer does not have to specify in detail how or where the data are to be found.
HOW A DBMS SOLVES THE PROBLEMS OF THE TRADITIONAL FILE ENVIRONMENT
A DBMS can reduce data redundancy and inconsistency by minimizing isolated files in which the same data are repeated. The DBMS may not enable the organization to eliminate data redundancy entirely, but it can help control redundancy. Even if the organization maintains some redundant data, using a DBMS eliminates data inconsistency because the DBMS can help the organization ensure that every occurrence of redundant data has the same values. The DBMS uncouples programs and data, enabling data to stand on their own. Access and availability of information can be increased and program development and maintenance costs can be reduced because users and programmers can perform ad hoc queries of data in the database. The DBMS enables the organization to centrally manage data, their use, and security.
The Window on Organizations illustrates some of the benefits of a DBMS for information management. Procter & Gamble had to manage massive amounts of product data for its more than 300 brands. Because these data were stored in 30 separate repositories, the company could not easily bring together information about the companys various products and their components, degrading operational efficiency. Management of these data improved once P&G created a common set of technical standards for all its products and organized its data in a single global database.
Types of Databases
Contemporary DBMS use different database models to keep track of entities, attributes, and relationships. Each model has certain processing advantages and certain business advantages.
RELATIONAL DBMS
The most popular type of DBMS today for PCs as well as for larger computers and mainframes is the relational DBMS. The relational data model represents all data in the database as simple two-dimensional tables called relations. Tables may be referred to as files. Information in more than one file can be easily extracted and combined.
Figure 7-6 shows a supplier table and a part table. In each table the rows represent unique records and the columns represent fields, or the attributes that describe the entities. The correct term for a row in a relation is tuple. Often a user needs information from a number of relations to produce a report. Here is the strength of the relational model: It can relate data in any one file or table to data in another file or table as long as both tables share a common data element.
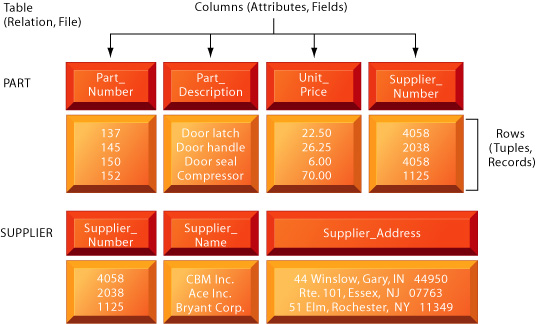 |
FIGURE 7-6 The relational data model
Each table is a relation, each row
is a tuple representing a record,
and each column is an attribute
representing a field. These relations
can easily be combined and
extracted to access data and produce
reports, provided that any
two share a common data element.
In this example, the PART
and SUPPLIER files share the
data element Supplier_Number.
In a relational database, three basic operations, as shown in Figure 7-7, are used to develop useful sets of data: select, project, and join. The select operation creates a subset consisting of all records in the file that meet stated criteria. In our example, we want to select records (rows) from the part table where the part number equals 137 or 152. The join operation combines relational tables to provide the user with more information than is available in individual tables. In our example, we want to join the now-shortened part table (only parts numbered 137 or 152 will be presented) and the supplier table into a single new table.
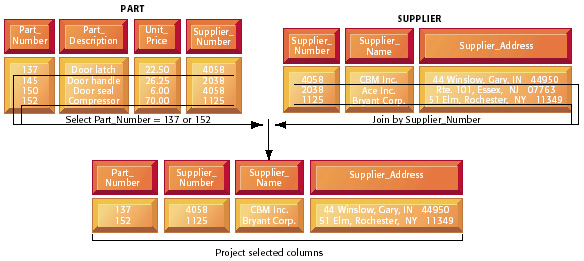 |
FIGURE 7-7 The three basic operations of a relational DBMS
The select, project, and join operations enable data from two different tables to be combined and only
selected attributes to be displayed.
The SQL statements for producing the new resultant table in Figure 7-7 would be as follows:
SUPPLIER.Supplier_Address
FROM PART, SUPPLIER
WHERE PART.Supplier_Number = SUPPLIER.Supplier_Number AND Part_Number = 137 OR Part_Number = 152;
You can learn more about SQL and how to create a SQL query in the Hands-On Guide to MIS at the end of this text.
Leading mainframe relational database management systems include IBMs DB2 and Oracle from the Oracle Corporation. DB2, Oracle, and Microsoft SQL Server are used as DBMS for midrange computers. Microsoft Access is a PC relational database management system, and Oracle Lite is a DBMS for small handheld computing devices.
Internet Connection
The Internet Connection for this chapter directs you to a series of Web sites where you can complete an exercise to evaluate various commercial database management system products.
HIERARCHICAL AND NETWORK DBMS
You can still find older systems that are based on a hierarchical or network data model. The hierarchical DBMS is used to model one-to-many relationships, presenting data to users in a treelike structure. Within each record, data elements are organized into pieces of records called segments. To the user, each record looks like an organizational chart with one top-level segment called the root. An upper segment is connected logically to a lower segment in a parentchild relationship. A parent segment can have more than one child, but a child can have only one parent.
Figure 7-8 shows a hierarchical structure that might be used for a human resources database. The root segment is Employee, which contains basic employee information such as name, address, and identification number. Immediately below it are three child segments: Compensation (containing salary and promotion data), Job Assignments (containing data about job positions and departments), and Benefits (containing data about beneficiaries and benefit options). The Compensation segment has two children below it: Performance Ratings (containing data about employees job performance evaluations) and Salary History (containing historical data about employees past salaries). Below the Benefits segment are child segments for Pension, Life Insurance, and Health, containing data about these benefit plans.
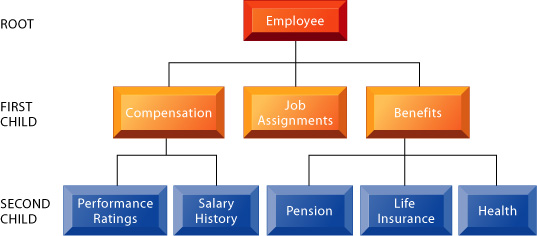 |
FIGURE 7-8 A hierarchical database for a human resources system
The hierarchical database model
looks like an organizational chart
or a family tree. It has a single
root segment (Employee) connected
to lower level segments
(Compensation, Job Assignments,
and Benefits). Each subordinate
segment, in turn, may connect to
other subordinate segments.
Here, Compensation connects to
Performance Ratings and Salary
History. Benefits connects to
Pension, Life Insurance, and
Health. Each subordinate segment
is the child of the segment
directly above it.
Whereas hierarchical structures depict one-to-many relationships, network DBMS depict data logically as many-to-many relationships. In other words, parents can have multiple children, and a child can have more than one parent. A typical many-to-many relationship for a network DBMS is the studentcourse relationship (see Figure 7-9). There are many courses in a university and many students. A student takes many courses, and a course has many students.
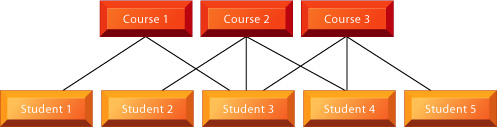 |
FIGURE 7-9 The network data model
This illustration of a network data
model showing the relationship
the students in a university have
to the courses they take represents
an example of logical
many-to-many relationships.
Hierarchical and network DBMS are considered outdated and are no longer used for building new database applications. They are much less flexible than relational DBMS and do not support ad hoc, English languagelike inquiries for information. All paths for accessing data must be specified in advance and cannot be changed without a major programming effort. For instance, if you queried the human resources database illustrated in Figure 7-8 to find out the names of the employees with the job title of administrative assistant, you would discover that there is no way the system can find the answer in a reasonable amount of time. This path through the data was not specified in advance.
Relational DBMS, in contrast, have much more flexibility in providing data for ad hoc queries, combining information from different sources, and providing capability to add new data and records without disturbing existing programs and applications. However, these systems can be slowed down if they require many accesses to the data stored on disk to carry out the select, join, and project commands. Selecting one part number from among millions, one record at a time, can take a long time. Of course, the database can be tuned to speed up prespecified queries.
Hierarchical DBMS can still be found in large legacy systems that require intensive high-volume transaction processing. Banks, insurance companies, and other highvolume users continue to use reliable hierarchical databases, such as IBMs Information Management System (IMS) developed in 1969. As relational products acquire more muscle, firms will shift away completely from hierarchical DBMS, but this will happen over a long period of time.
OBJECT-ORIENTED DATABASES
Conventional database management systems were designed for homogeneous data that can be easily structured into predefined data fields and records organized in rows and columns. But many applications today and in the future will require databases that can store and retrieve not only structured numbers and characters but also drawings, images, photographs, voice, and full-motion video. Conventional DBMS are not well suited to handling graphics-based or multimedia applications. For instance, design data in a computer-aided design (CAD) database consist of complex relationships among many types of data. Manipulating these kinds of data in a relational system requires extensive programming to translate complex data structures into tables and rows. An objectoriented DBMS, however, stores the data and procedures that act on those data as objects that can be automatically retrieved and shared.
Object-oriented database management systems (OODBMS) are becoming popular because they can be used to manage the various multimedia components or Java applets used in Web applications, which typically integrate pieces of information from a variety of sources. OODBMS also are useful for storing data types such as recursive data. (An example would be parts within parts as found in manufacturing applications.) Finance and trading applications often use OODBMS because they require data models that must be easy to change to respond to new economic conditions.
Although object-oriented databases can store more complex types of information than relational DBMS, they are relatively slow compared with relational DBMS for processing large numbers of transactions. Hybrid object-relational DBMS are now available to provide capabilities of both object-oriented and relational DBMS. A hybrid approach can be accomplished in three different ways: by using tools that offer object-oriented access to relational DBMS, by using object-oriented extensions to existing relational DBMS, or by using a hybrid object-relational database management system.
 |
|