
João Reis
Researcher and Invited Teacher @ FEUP
My name is João Reis, and I’m currently an Invited Teacher at FEUP and a Researcher at the Institute for Systems and Robotics – Porto,
where I’m responsible for both management and technical developments in three European Founded Projects. I'm also a Doctoral Student
in Informatics Engineering at FEUP focused on the Machine Learning domain.
There are patterns that we cannot even perceive due to our lenience of considering a simple leaf fall, raining drops or random persons’
organization in room office as a routinely meaningless event. All we need is just to look again with the right method of questioning.
Is based on this simple moto first introduced by Werner Heisenberg that expresses my eager interest for the machine learning and pattern
recognition domain. It’s my natural curiosity about all that moves around that opens the door for the minimum assumption that possibly
there are some sort of non-obvious correlations between, and fosters my need to grasp the true value of patterns and its consequent beauty.
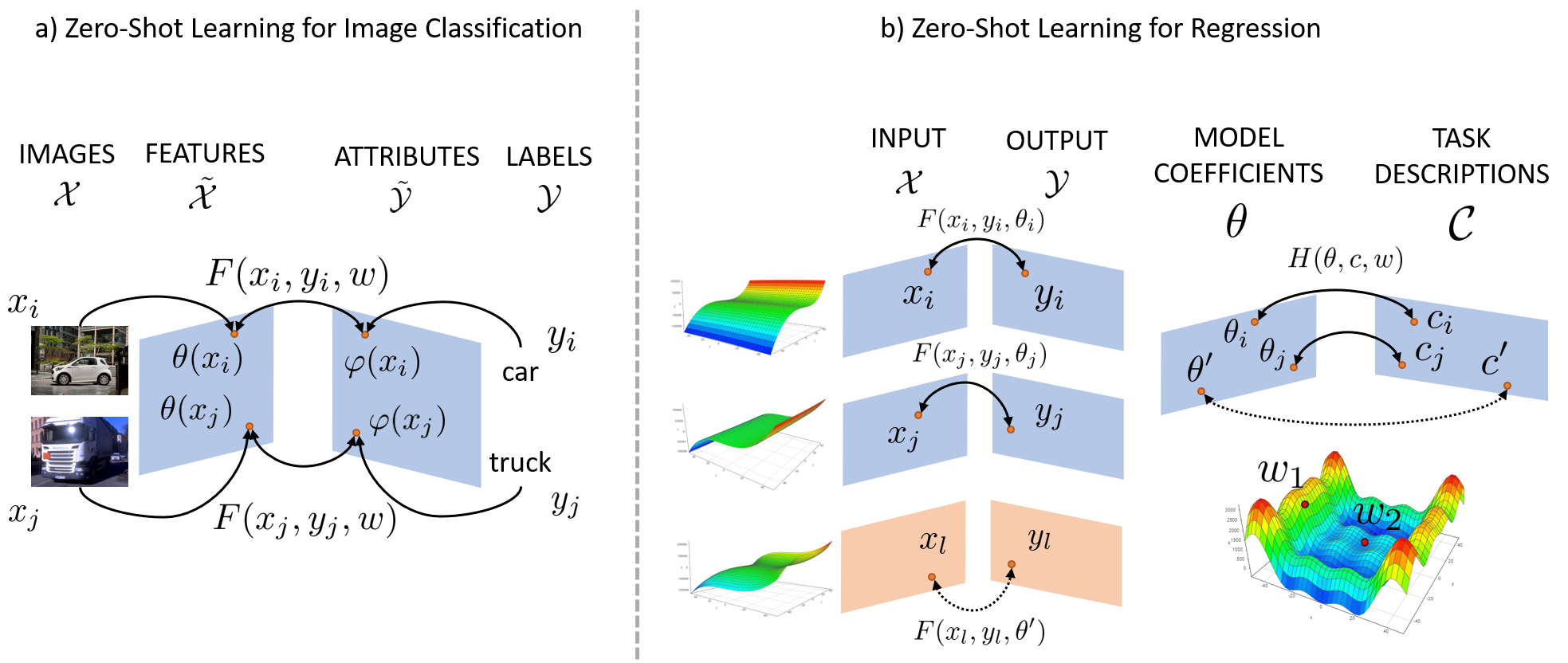 Figure 1: Comparison between ZSL for image classification and regression. a) Case where a latent representation for both images and classes is used, and a compatibility between these is learned (Akata et al., 2015). b) Case where multiple models are used to learn a hyper-model that maps model coefficients
Figure 1: Comparison between ZSL for image classification and regression. a) Case where a latent representation for both images and classes is used, and a compatibility between these is learned (Akata et al., 2015). b) Case where multiple models are used to learn a hyper-model that maps model coefficients 
